I was preparing a second post on the history of dynamic programming algorithms, when another topic caught my attention. There is a common belief among developers that regular expression engines in Perl, Java, and several other languages are fast. This has been my belief as well. However, I was dumbfound by a discovery that these engines always rely on a pre-historic backtracking approach (with partial memoization), which can be very slow. In some pathological cases, their run-time is exponential in the length of the text and/or pattern. Non-believers can check out my sample code. What is especially shocking is that efficient algorithms were known already in the 1960s. Yet, most developers were unaware. There are certain cases, when one has to use backtracking, but these cases are rare. For the most part, a text can be matched against a regular expression via a simulation of a non-deterministic or deterministic finite state automaton. If you are familiar with the concept of the finite state automaton, I encourage you to read the whole story here. The other readers may benefit from reading this post to the end.
A finite state automaton is an extremely simple concept, but it is usually presented in a very formal way. Hence, a lot of people fail to understand it well. One can visualize a finite state automaton as a robot moving from floor to floor of a building. Floors represent automaton states. An active state is a floor where the robot is currently located. The movements are not arbitrary: the robot follows commands. Given a command, the robot moves to another floor or remains on the same floor. This movement is not solely defined by the command, but rather by a combination of the command and the current floor. In other words, a command may work differently on each floor.
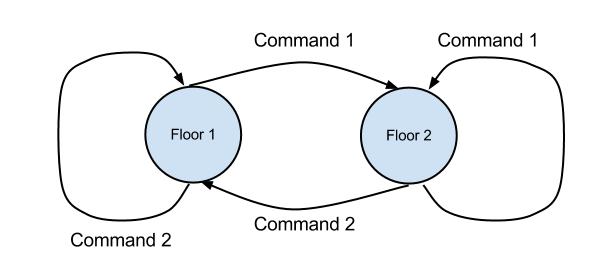
Figure 1. A metaphoric representation of a simple automaton by a robot moving among floors.
Consider a simple example in Figure 1. There are only two floors and two commands understandable by the robot. If the robot is on the first floor, the Command 2 tells the robot to remain on this floor. This is denoted by a looping arrow. However, the Command 1 makes the robot move to the second floor.
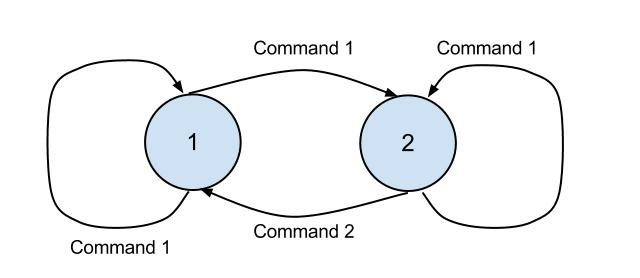
Figure 2. A non-deterministic automaton.
A deterministic robot is very diligent and can only process unambiguous commands. A non-deterministic robot has more freedom and is capable of processing ambiguous commands. Consider an example of a non-deterministic automaton in Figure 2. If the robot is on the first floor and receives Command 1, it may choose to stay on the first floor, or to move to the second floor. Furthermore, there may be floors where robot's behavior is not defined for some of the commands. For example, in Figure 2, if the robot is on the first floor, it does not know where to move on receiving Command 2. In this case, the robot simply got stuck, i.e., the automaton fails.
In the robot-in-the-building metaphor, a building floor is an automaton state and a command is a symbol in some alphabet. The finite state automaton is a useful abstraction, because it allows us to model special text recognizers known as regular expressions. Imagine that a deterministic robot starts from the first floor and follows the commands defined by text symbols. He executes these commands one by one and moves from floor to floor. If all commands are executed and the robot stops on the last floor (the second floor in our example), we say that the automaton recognizes the text. Note that the robot may visit the last floor several times, but what matters is whether it stops on the last floor or not.
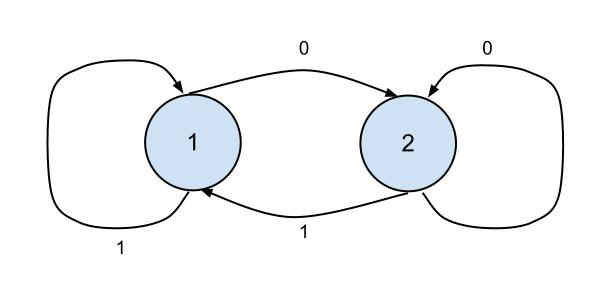
Figure 3. A finite state automaton recognizing binary texts that end with 0.
Consider an example of a deterministic automaton/robot in Figure 3, which works with texts written in the binary alphabet. One can see that the robot recognizes a text if and only if (1) the text is non-empty and (2) the last symbol is zero. Indeed, whenever the robot reads the symbol 1, it either moves to or remains on the first floor. When it reads the symbol 0, it either moves to or remains on the second floor. For example, for the text 010, the robot first follows the command to move to floor two. Then, it reads the next command (symbol 1), which makes it return to floor one. Finally, the robot reads the last command (symbol 0) and moves to the final (second) floor. Thus, the automaton recognizes the string 010. There is a well-known relationship between finite automata and regular expressions. For each regular expression there exists an equivalent automaton and vice versa. For instance, in our case the automaton is defined by the regular expression: 0$.
The robot/automaton in Figure 3 is deterministic. Note, however, that not all regular expressions can be easily modeled using a deterministic robot/automaton. In most cases, a regular expression is best represented by a non-deterministic one. For the deterministic robot, a sequence of symbols/commands fully determines the path (i.e., a sequence of floors) of the robot in the building. As noted previously, if the robot is not deterministic, in certain cases, it may choose several different paths after reading the same command (being also on the same floor). A choice of the path is not arbitrary: some paths are not legitimate (see Figure 2), yet we do not know for sure what is the exact sequence of the floors that the robot will visit. When does the non-deterministic robot recognize the text? The answer is simple: there should be at least one legitimate path that starts on the first and ends on the last floor. If no such path exists, the text is not recognized. From the computational perspective, we need to either find this path or to prove that no such path exists.
A naive approach to find a path that ends on the last floor involves a recursive search. The robot starts from the first floor and reads one symbol/command after another. If the command and the source floor unambiguously define the next floor, the robot simply goes to this floor. Because the robot is not deterministic, there may be more than one target floor sometimes, or no target floors at all. For example, in Figure 2, if the robot is on the first floor and receives the Command 1, it can either move to the second floor or stay on the first floor. However, it cannot process Command 2 on the first floor. If there is more than one target floor, the robot memorizes its state (by creating a checkpoint) and chooses to explore any of the legal target floors recursively. If the robot reaches the place, where no target floors exist, it returns to the last checkpoint and continues to explore (yet unvisited) floors starting from this checkpoint. This method is known as backtracking.
The backtracking approach can be grossly inefficient and may have exponential run-time. A more efficient robot should be able to clone itself and merge together several clones when it is necessary. Whenever the robot has a choice where to move, it clones itself and moves to all possible target floors. However, if several clones meet at the same floor, they merge together. In other words, we have a “Schrodinger” robot that is present on several floors at the same time! Surprisingly enough, this interpretation is often challenged by people, who believe that it does not truly represent the phenomenon of the non-deterministic robot/automaton. Yet, it does and, in fact, this representation is very appealing from the computational perspective. To implement this approach, one should keep a set of floors, where the robot is present. This set of floors corresponds to active states of the non-deterministic automaton. On receiving the next command/symbol, we go over these floors and compute a set of legitimate target floors (where the robot can move to). Then, we simply merge these sets and obtain a new set of active floors (occupied by our Schrodinger robot).
This method was obvious to Ken Thompson in 1960s, but not obvious to the implementers of the backtracking approach in Perl and other languages. I reiterate that classic regular expressions are always equivalent to automata and vice versa. However, there are certain extensions that are not. In particular, regular expressions with backreferences cannot be generally represented by automata. Oftentimes, if a regular expression contains backreferences, the potentially inefficient backtracking approach is the only way to go. However, in most cases regular expressions do not have backreferences, and can be efficiently processed by a simulation of the non-deterministic finite state automaton. The whole process can be made even more efficient through partial or complete determinization.
Edited by Anna Belova
Comments
Perhaps you would be interested to look at redgrep, a new regular expression engine from Google: http://mirror.linux.org.au/linux.conf.au/2013/mp4/redgrep_from_regular_expression_derivatives_to_LLVM.mp4
redgrep at Google Code:
http://code.google.com/p/redgrep/
Thanks! Stashed the link. How does it compare to RE2?
It depends on regular expression. In some cases redgrep is faster, while RE2 beats it in others.
If I understand correctly, redgrep is 100% DFA. Similar to Yandex's PIRE. So, it is not surprising that they beat RE2, which is only partial, on-the-fly, DFA. RE2 should be able to work with less memory.
re2 is not 100% DFA, because (they claim) 100% DFA is not always faster, due to cache misses.
Hi Elazar, thank you for stopping by. Yes, I believe it's a lazy DFA, which is constructed on the fly. I guess that a true DFA can beat it in many cases, but RE2 would use less memory. It would still be useful, if there is not enough memory to construct the complete DFA.