Attention folks working on LONG-document ranking & retrieval! We found evidence of a very serious issue in existing long-document collections, most importantly MS MARCO Documents. It can potentially affect all papers comparing different architectures for long document ranking.
Do not get us wrong: We love MS MARCO: It has been a fantastic resource that spearheaded research on ranking and retrieval models. In our work we use MS MARCO both directly as well as its derivative form: MS MARCO FarRelevant.
Yet MS MARCO (and similar collections) can have substantial positional biases which not only "mask" differences among existing models, but also prevent MS MARCO trained models from performing well on some other collections.
This is not a modest degradation where performance drops roughly to BM25 level (as we observed, e.g., in our prior evaluation).. It can be a dramatic drop in accuracy down to the random baseline level.
We found a substantial positional bias of relevant information in standard IR collections, which include MS MARCO Documents and Robust04. However, judging from other paper results a lot of other collections are affected.
Because relevant info tends to be in the beginning of a doc we often do not need a special long-context model to do well in ranking and retrieval. The so-called FirstP model (truncation to < 512 tokens) can do well (see the picture, we do not plot FirstP explicitly, but all the numbers are relative to FirstP efficiency or accuracy):
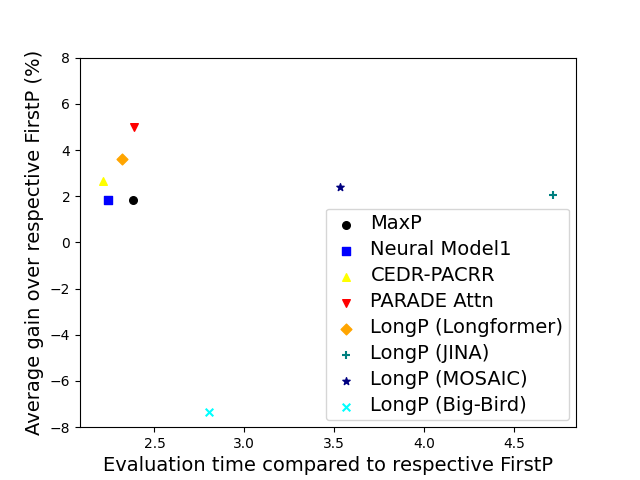
So how do we prove positional bias is real? There is no definitive evidence, but we provide several evidence pieces. In doing so we introduce a NEW synthetic collection MS MARCO Far Relevant which does not have relevant passages in the beginning.
- On MS MARCO we trained 20+ rank models (including two FlashAttention-based models) and observed all of them to barely beat FirstP (in rare cases models underperformed FirstP);.
- We analyzed positions of relevant passages and found these to be skewed to the beginning;
- We 0-shot tested & then fine-tuned models on MS MARCO Far Relevant.
Unlike standard collections where we observed both little benefit from incorporating longer contexts & limited variability in model performance (within a few %), experiments on MS MARCO FarRelevant uncovered dramatic differences among models.
-
To begin with, FirstP models performed roughly at the random-baseline level in both 0-shot and fine-tuning scenarios (see the picture below).
-
Second, simple aggregation models including MaxP and PARADE Attention had good zero-shot accuracy, but benefited little from fine-tuning.
-
In contrast, most other models had poor 0-shot performance (roughly at a random baseline level), but outstripped MaxP by as much as 13-28% after fine-tuning. Check out the lines connecting markers in left and right columns:
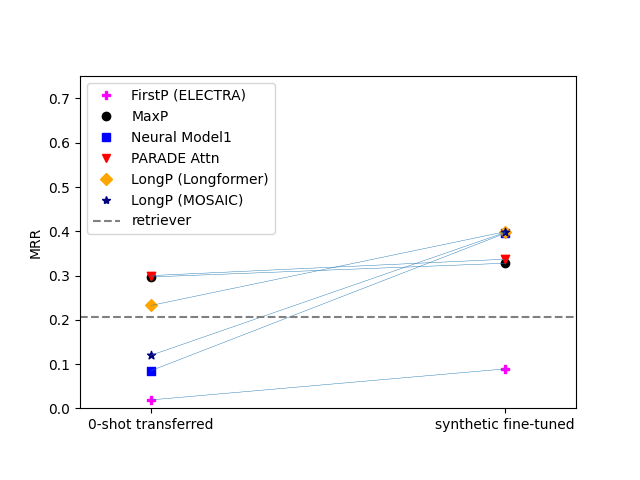
Best models? PARADE models were the best and markedly outperformed FlashAttention-based models, Longformer as well as chunk-and-aggregate approaches. PARADE Attention performed best on standard collection (in most cases) and in the zero-shot transfer model on MS MARCO FarRelevant. However, among fine-tuned models on MS MARCO Far Relevant, the best was PARADE Transformer (with a randomly initialized aggregator model).
This paper is an upgrade of 2021 preprint enabled by a great collaborator David Akinpelu as well as by the team of former CMU (MCDS) students. David, specifically, did a ton of work including implementation of recent baselines.
Paper link.
Code/Data link